ps:低水平半机翻 linux5.4 Documentation/RCU/whatisRCU
请注意,“什么是 RCU?” LWN 系列是一个开始学习 RCU 的好地方。
- 什么是 RCU? 根本 http://lwn.net/Articles/262464/
- 什么是 RCU? 第二部分:用法 http://lwn.net/Articles/263130/
- RCU 第三部分: RCU API http://lwn.net/Articles/264090/
- RCU API, 2010 版 http://lwn.net/Articles/418853/
2010 API 表 http://lwn.net/Articles/419086/
- RCU API, 2014 版 http://lwn.net/Articles/609904/
2014 API 表 http://lwn.net/Articles/609973/
什么是 RCU?
RCU是一种同步机制,在2.5版过程工作中添加到Linux内核,该机制已对大部分读取操作进行了优化。 一旦你理解了他 RCU 其实相当的简单,但是理解他有时会是一个挑战。 一部分问题在于过去对 RCU 的大多数描述都是在错误地假设下编写并且被当作对 RCU “唯一正确的” 描述。 相反,已有的经验是不同的人必须走不同的路径去理解 RCU。 如下所示:
喜欢从概念概述入手的人应该看第一章(1. RCU 概述),尽管大多数读者可以通过阅读本章内容而在一些点上受益。 喜欢从可以尝试的 API 开始的人应该看第二章(2. 什么是 RCU 的核心 API?)。 喜欢从示例使用开始的人们应该看第三和第四章(3. 核心 RCU API 的一些用法示例?,4. 如果我的更新线程无法阻塞怎么办?)。 需要了解RCU实现的人们应该读第5章(5. 什么是 RCU 的简单实现?), 然后深入了解内核源码。 通过推理最理性的人应该关注第6章(6. 读写锁定的模拟)。 第7章(7. 完整 RCU API 列表)是 API 文档的索引,第8节(8. 快速测验答案)是惯例的关键答案。
因此,从对你最有意义的章节以和你比较喜欢的学习方法开始。 如果你需要了解所有内容,请随时阅读整个内容 — 但是,如果你真的是那种人,那么你还会细读源码,因此永远也不需要这篇文档。 😉
1. RCU 概述
RCU的基本思想是将更新分为“删除”和“回收”两个阶段。 删除阶段删除对数据结构中数据项的引用(可能将其替换为对这些数据项新版本的引用),并且可以与读者并发进行。 与读者并发进行的删除阶段是安全的,因为现代 CPU 的语义保证读者将看到数据结构的旧版本或新版本之一,而不是部分更新的引用。 回收阶段回收(例如,释放)在删除阶段从数据结构中删除的数据项。 由于回收数据项可能会干扰任何同时引用这些数据项的读者,因此,在读者不再引用这些数据项之前,回收阶段不得开始。
将更新分为删除和回收阶段,允许更新程序立即执行删除阶段,并推迟回收阶段,直到所有在删除阶段活跃的读者都完成为止,方法是阻塞直到读者读完,或者注册一个回调,在读者读完之后调用。 只需要考虑在删除阶段处于活跃状态的读者,因为在删除阶段之后启动的任何读取将无法获得对已删除数据项,因此不会受到回收阶段的干扰。
因此,典型的RCU更新序列如下所示:
a. 删除指向数据结构的指针,以便后续的读者无法获得对该结构的引用。 b. 等待以前的所有读者完成其RCU读取侧临界部分。 c. 在没有任何读者拥有对数据结构的引用时,可以安全地对其进行回收(例如,kfree()d)。
上面的步骤(b)是 RCU 延迟销毁的主要中心思相。 等待所有读者读完的能力使 RCU 的读者可以使用轻量级的同步,在某些情况下,完全没有同步。 相反,在更常规的基于锁的方案中,读者必须使用重量级同步,以防止更新程序在他们读取时删除数据结构。 这是因为基于锁的更新通常更新数据项时,并且必须排除其他读者。 相反,基于 RCU 的更新通常利用以下事实带来的优点:在现代 CPU 上对单个对齐的指针进行写操作是原子的,允许对链表结构中的数据项进行原子插入,删除和替换而不会干扰读者。 并发的 RCU 读者可以继续访问旧版本,并且可以省去在当前 SMP 计算机系统上代价高的原子操作,内存障碍和通信高速缓存未命中的问题,甚至没有锁的争用。
在上面显示的三步过程中,更新程序同时执行删除和回收步骤,但是通常对于完全不同的线程进行回收很有用,实际上,在Linux内核的目录条目缓存就是这种情况 (dcache)。 即使同一线程同时执行更新步骤(上述步骤(a))和回收步骤(上述步骤(c)),将它们分开考虑通常也很有帮助。 例如, RCU 读者和更新程序完全不需要通信,但是 RCU 在读者和回收程序之间提供隐式的低开销通信,在上述步骤(b)中。
因此,假设读者没有进行任何类型的同步操作,回收程序如何才能知道读者何时完成工作? 继续阅读以了解RCU的API如何简化此过程。
2. 什么是 RCU 的核心 API?
RCU 的核心 API 是相当的少:
a. rcu_read_lock() b. rcu_read_unlock() c. ynchronize_rcu() / call_rcu() d. rcu_assign_pointer() e. rcu_dereference()
RCU API还有许多其他成员,但是其余大多数可以用这五个来表达,尽管大多数实现都用 call_rcu() 回调 API 来取代 syncnize_rcu()。
下面是五个核心 RCU API ,其他18个将在后面列举。 有关更多信息,请参见内核文档,或直接查看函数头的注释。
rcu_read_lock()
void rcu_read_lock(void); 读者用于通知回收函数读者正在进入 RCU 读取侧的临界区域。 尽管使用 CONFIG_PREEMPT_RCU 构建的内核可以抢占 RCU 读端临界区,但在 RCU 的读端临界区中进行阻止是非法的。 确保在 RCU 读端临界区访问的任何受 RCU 保护的数据结构在临界区持续时间内都不会被回收。 引用计数可以用于与 RCU 结合来维护对长期引用的数据结构。
rcu_read_unlock()
void rcu_read_unlock(void); 读取端用于通知回收端读取端正在退出 RCU 读端临界区。 注意,RCU读端临界区可能是嵌套的 和/或 重叠的。
synchronize_rcu()
void synchronize_rcu(void); 标记更新程序代码的结尾和回收程序代码的开头。 它会阻塞直到所有CPU上所有预先存在的 RCU 读端临界区都完成。 请注意,synchronize_rcu() 不一定会等待任何后续的 RCU 读端临界区完成。 例如,考虑以下事件序列:
| CPU 0 | CPU 1 | CPU 2 | |
|---|---|---|---|
| 1. | rcu_read_lock() | ||
| 2. | enters synchronize_rcu() | ||
| 3. | rcu_read_lock() | ||
| 4. | rcu_read_unlock() | ||
| 5. | exits synchronize_rcu() | ||
| 6. | rcu_read_unlock() |
重申一下,syncnize_rcu() 仅等待正在进行的 RCU 读端临界区完成,而不必等待调用 syncize_rcu() 之后开始的任何部分。 当然,在最后一个预先存在的 RCU 读端临界区完成后,synchronize_rcu() 不一定会立即返回。 一方面,可能存在调度延迟。 另一方面,许多 RCU 实现批量处理请求以提高效率,这可能会进一步延迟 syncnize_rcu() 返回。 由于 syncnize_rcu() 是确定指出读端读取完成API,因此其实现是 RCU 的关键。 为了使 RCU 在大多数读取密集的情况下都可用,synchronize_rcu() 的开销也必须非常小。 call_rcu() API 是 syncnize_rcu() 的回调形式,在后面的部分中有更详细的描述。 它并不阻塞,而是注册一个函数和被调用的参数,这个函数在所有正在进行的 RCU 读端临界区完成之后被调用。 在禁止阻塞或读端临界区性能至关重要的情况下,此回调变体特别有用。 但是,不应轻易使用 call_rcu() API,因为使用 syncnize_rcu() API 通常会使代码更简单。 此外,synchronize_rcu() API 具有不错的属性,可以在宽限期被延迟时自动限制更新速率。 面对拒绝服务攻击,此属性让系统具有弹性。使用 call_rcu() 的代码应限制更新速率,以获得相同的弹性。 有关限制更新速率的一些方法,请参见checklist.txt。
rcu_assign_pointer()
void rcu_assign_pointer(p, typeof(p) v); 是的,rcu_assign_pointer() -的实现是一个宏,尽管能够以这种方式声明一个函数很酷。 (毫无疑问,编译专家会对此表示反对。) 更新程序使用此函数将分配一个新值给受 RCU 保护的指针,以便安全地将值的更改从更新侧传达到读取端。 此宏的结果不是右值,但会执行给定CPU体系结构所需的任何内存屏障指令。 也许同样重要,它用于记录(1)哪些指针受RCU保护以及(2)给定结构可供其他 CPU 访问的点。 也就是说,rcu_assign_pointer() 间接使用最频繁的,通过 _rcu 列表操作原语(例如 list_add_rcu())。
rcu_dereference()
typeof(p) rcu_dereference(p); 与 rcu_assign_pointer() 一样,rcu_dereference() 必须实现为宏。 读取端使用 rcu_dereference() 来获取受 RCU 保护的指针,该指针返回一个可以安全解引用的值。 请注意,rcu_dereference()实际上并未取消对指针的引用,相反,它保护指针供后续取消引用。 它还执行给定的 CPU 体系架构所需要的任何内存屏障指令。 当前,只有 Alpha 架构才需要 rcu_dereference() 中的内存屏障-在其他 CPU 上,它编译为什么也不做,甚至没有编译指令。 通用编码实践使用 rcu_dereference() 将受RCU保护的指针复制到本地变量,然后取消引用此本地变量,例如,如下所示:
p = rcu_dereference(head.next); return p->data;
然而,在这种情况下,可以很容易地将它们组合成一条语句:
return rcu_dereference(head.next)->data;
如果要从受RCU保护的结构中获取多个字段,首先应当使用局部变量。 重复的 rcu_dereference() 调用看起来丑,如果在临界区发生更新,则不保证将返回相同的指针,并且在 Alpha CPU 上会产生不必要的开销。 请注意,rcu_dereference()返回的值仅在当前锁定的 RCU 读端临界区[1]中有效。 例如,以下内容不合法:
rcu_read_lock(); p = rcu_dereference(head.next); rcu_read_unlock(); x = p->address; /* BUG!!! */ rcu_read_lock(); y = p->data; /* BUG!!! */ rcu_read_unlock();
保持对一个 RCU 读端临界区的引用到另一个读端临界区是非法的,在基于锁的临界区保持引用到另一个临界区一样非法! 同样,在临界区以外的地方像在正常锁定条件下进行引用一样非法。 与 rcu_assign_pointer() 一样,rcu_dereference() 的重要功能是记录哪些指针受RCU保护,尤其是标记一个随时可能更改的指针,紧跟在 rcu_dereference() 之后。 并且,同样类似于 rcu_assign_pointer(),使用 rcu_dereference() 间接的通过 _rcu 列表操作原语(例如 list_for_each_entry_rcu())。 [1]变量 rcu_dereference_protected() 可以在 RCU 读端临界区外使用,只要使用情况受到更新侧代码获取的锁的保护即可。 此变体避免了使用(例如)不带 rcu_read_lock() 保护的 rcu_dereference() 时发生的 lockdep 警告。 使用 rcu_dereference_protected() 还具有允许编译器优化的优点而 rcu_dereference() 必须禁止。 rcu_dereference_protected() 变量采用 lockdep 表达式,以指示调用者必须获取哪些锁。 如果未提供指示的保护,则会发出 lockdep splat。 有关更多详细信息和示例用法,请参见 RCU/Design/Requirements/Requirements.html 和 API 的代码注释。
下图显示了每个API如何在读端,更新侧和回收侧之间进行通信。
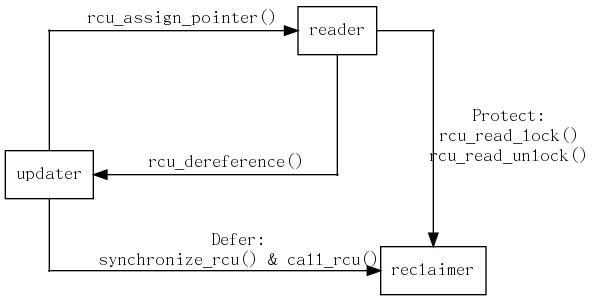
RCU 基础结构观察 rcu_read_lock(), rcu_read_unlock(), synchronize_rcu() 和 call_rcu() 调用的时间顺序,以确定何时(1)syncnize_rcu() 调用何时可以返回其调用者以及(2)call_rcu() 回调 可以被调用。 RCU基础结构的有效实现大量使用批处理,以便在相应API的许多使用上分摊其开销。
在Linux内核中,至少有三种RCU用法。上图显示了最常见的一种。 在更新端,所使用的 rcu_assign_pointer(), sychronize_rcu() 和 call_rcu() 三种类型使用的原语都是相同的。 但是,为了更好的保护(在读者方面),所使用的原语会根据情况而有所不同:
a. rcu_read_lock() / rcu_read_unlock() rcu_dereference() b.rcu_read_lock_bh() / rcu_read_unlock_bh() local_bh_disable() / local_bh_enable() rcu_dereference_bh() c.rcu_read_lock_sched() / rcu_read_unlock_sched() preempt_disable() / preempt_enable() local_irq_save() / local_irq_restore() hardirq enter / hardirq exit NMI enter / NMI exit rcu_dereference_sched()
这三种类型的用法如下:
1. RCU 用于普通数的据结构。 2. RCU 用于可能受到 Dos 攻击的网络数据结构。 3. RCU 用于调度和中断/NMI处理程序任务。
重申,大多数情况使用(a)。 (b)和(c)情况对于特定的用法是很重要的,但相对比较少见。
3. 核心 RCU API 的一些用法示例?
本节显示了核心 RCU API 的简单用法,以保护指向动态分配结构的全局指针。 RCU 的更典型用途可以在 listRCU.txt, arrayRCU.txt 和 NMI-RCU.txt 中找到。
struct foo {
int a;
char b;
long c;
};
DEFINE_SPINLOCK(foo_mutex);
struct foo __rcu *gbl_foo;
/*
* 创建一个新的结构 foo,该结构与 gbl_foo 当前指向的结构 foo 相同,
* 只不过字段 “a” 被 “new_a” 替换。将 gbl_foo 指向新结构,
* 并在宽限期过后释放旧结构。
*
* 使用 rcu_assign_pointer() 确保并发读者看到新结构初始化过的版本。
*
* 使用 syncnize_rcu() 来确保在释放旧结构之前,
* 所有可能引用旧结构的读者都已完成。
*/
void foo_update_a(int new_a)
{
struct foo *new_fp;
struct foo *old_fp;
new_fp = kmalloc(sizeof(*new_fp), GFP_KERNEL);
spin_lock(&foo_mutex);
old_fp = rcu_dereference_protected(gbl_foo, lockdep_is_held(&foo_mutex));
*new_fp = *old_fp;
new_fp->a = new_a;
rcu_assign_pointer(gbl_foo, new_fp);
spin_unlock(&foo_mutex);
synchronize_rcu();
kfree(old_fp);
}
/*
* 返回当前 gbl_foo 结构字段 “a” 的值。
* 使用 rcu_read_lock() 和 rcu_read_unlock()
* 确保该结构不会从他们之间删除删除,并使用 rcu_dereference()
* 确保我们看到该结构的初始化过版本
* (对于 DEC Alpha 和阅读代码的人来说很重要)。
*/
int foo_get_a(void)
{
int retval;
rcu_read_lock();
retval = rcu_dereference(gbl_foo)->a;
rcu_read_unlock();
return retval;
}
因此,总结一下:
- 使用 rcu_read_lock() 和 rcu_read_unlock() 来保护 RCU 读端临界区。
- 在 RCU 读端临界区中,使用 rcu_dereference() 去间接访问受 RCU 保护的指针。
- 使用一些可靠的方案(例如锁或信号量)可以防止并发更新相互干扰。
- 使用 rcu_assign_pointer() 更新受 RCU 保护的指针。这个原语保护并发读者免受更新程序的干扰,而不是彼此并发更新! 因此,你仍然需要使用锁定(或类似方法)来防止并发的 rcu_assign_pointer() 原语相互干扰。
- 在从受RCU保护的数据结构中删除数据元素之后,但在回收/释放数据元素之前,请使用 syncnize_rcu() ,以便等待所有可能引用该数据项的 RCU 读端临界区的完成。
有关使用 RCU 时要遵循的其他规则,请参见 checklist.txt。 同样,可以在 listRCU.txt, arrayRCU.txt 和 NMI-RCU.txt 中找到 RCU 更典型的用法。
4. 如果我的更新线程无法阻塞怎么办?
在上面的示例中,foo_update_a() 一直阻塞,直到经过宽限期为止。 这很简单,但是在某些情况下,人们不能等待那么长时间-可能还要进行其他高优先级的工作。
在这种情况下,可以使用 call_rcu() 而不是 syncnize_rcu() 。 call_rcu() API如下:
void call_rcu(struct rcu_head * head,
void (*func)(struct rcu_head *head));
宽限期结束后,此函数将调用 func(head) 。 该调用可能发生在 softirq 或进程上下文中, 因此该函数不允许阻塞。foo 结构需要添加 rcu_head 结构,如下所示:
struct foo {
int a;
char b;
long c;
struct rcu_head rcu;
};
然后可以将foo_update_a()函数编写如下:
/*
* 创建一个新的结构 foo,该结构与 gbl_foo 当前指向的结构相同,
* 只不过字段 “a” 被 “new_a” 替换。
* 将 gbl_foo 指向新结构,并在宽限期过后释放旧结构。
*
* 使用 rcu_assign_pointer() 确保并发的读者看到新结构的初始化后版本。
*
* 使用 call_rcu() 来确保所有可能引用旧结构的读者在释放旧结构之前都已完成。
*/
void foo_update_a(int new_a)
{
struct foo *new_fp;
struct foo *old_fp;
new_fp = kmalloc(sizeof(*new_fp), GFP_KERNEL);
spin_lock(&foo_mutex);
old_fp = rcu_dereference_protected(gbl_foo, lockdep_is_held(&foo_mutex));
*new_fp = *old_fp;
new_fp->a = new_a;
rcu_assign_pointer(gbl_foo, new_fp);
spin_unlock(&foo_mutex);
call_rcu(&old_fp->rcu, foo_reclaim);
}
foo_reclaim()函数可能如下所示:
void foo_reclaim(struct rcu_head *rp)
{
struct foo *fp = container_of(rp, struct foo, rcu);
foo_cleanup(fp->a);
kfree(fp);
}
container_of() 原语是一个宏,给定指向结构的指针,结构的类型以及结构内的指向字段,该宏将返回指向结构开头的指针。
使用 call_rcu() 可以使 foo_update_a() 的调用方立即重新获得控制权,而不必担心新更新的元素的旧版本。 它还清楚地显示了 RCU 更新程序 foo_update_a() 和回收程序 foo_reclaim() 之间的区别。
忠告与上一节相同,只有这种情况使用 call_rcu() 而不是 syncnize_rcu():
- 在从受RCU保护的数据结构中删除数据元素之后,请使用 call_rcu() 注册一个回调函数, 该函数将在所有可能引用该数据项的 RCU 读端临界区完成后调用。
如果 call_rcu() 的回调除了在结构上调用 kfree() 外没有做其他事情,
kfree_rcu(old_fp, rcu);
同样,请参阅 checklist.txt ,以了解有关 RCU 使用的其他规则。
5. 什么是 RCU 的简单实现?
RCU 的优点之一是它具有极其简单的“玩具”实现,这是理解 Linux 内核中生产质量实现的良好第一步。 本节介绍两种“玩具”实现的 RCU,一种是按照熟悉的锁定原语实现的,另一种更类似于“经典” RCU。 两者对于现实世界的使用都太简单了,缺乏功能和性能。 但是,它们对于了解RCU的工作方式很有用。 有关生产质量的实现,请参见kernel/rcu/update.c, 并参考:http://www.rdrop.com/users/paulmck/RCU 描述Linux内核RCU实现的论文。 OLS’01 和 OLS’02 论文是一个很好的介绍,并且本文提供了有关 2004 年初的当前实现的更多细节。
5A. “玩具”实现 1:锁定
本节介绍基于熟悉的锁定原语的“玩具” RCU 实现。 它的开销使其无法用于实际使用,缺乏可伸缩性。 它也不适合实时使用,因为它允许调度延迟以从一个读端临界区“泄露”到另一个读端临界区。 它还假定递归读写锁:如果使用非递归锁尝c试此操作,并且允许嵌套的 rcu_read_lock() 调用,则可能会死锁。
但是,这可能是最简单的实现方式,因此是一个很好的起点。
这非常简单:
static DEFINE_RWLOCK(rcu_gp_mutex);
void rcu_read_lock(void)
{
read_lock(&rcu_gp_mutex);
}
void rcu_read_unlock(void)
{
read_unlock(&rcu_gp_mutex);
}
void synchronize_rcu(void)
{
write_lock(&rcu_gp_mutex);
smp_mb__after_spinlock();
write_unlock(&rcu_gp_mutex);
}
[你可以忽略rcu-assign-pointer()和rcu-dereference(),而不会遗漏太多内容。 但这里还是简化版本。不管你做什么,在使用RCU(提交补丁)时不要忘记它们!]
#define rcu_assign_pointer(p, v) \
({ \
smp_store_release(&(p), (v)); \
})
#define rcu_dereference(p) \
({ \
typeof(p) _________p1 = READ_ONCE(p); \
(_________p1); \
})
rcu_read_lock() 和 rcu_read_unlock() 原语通过读获取和释放全局读写锁。 syncnize_rcu() 原语写获取该相同的锁,然后释放它。 这意味着一旦 syncnize_rcu() 退出,就可以保证在调用 syncnize_rcu() 之前进行中的所有 RCU 读端临界区都已完成–否则 syncnize_rcu() 将无法获取写锁。 smp_mb__after_spinlock() 提供了 syncnize_rcu() 完整的内存屏障, 符合以下所列的“内存屏障保证”:Documentation/RCU/Design/Requirements/Requirements.html.
可以嵌套 rcu_read_lock(),因为可以递归获取读写锁。 还要注意,rcu_read_lock() 不会死锁(RCU的重要属性)。 这个原因是,唯一可以阻塞 rcu_read_lock() 的是 syncnize_rcu() 。 但是 syncnize_rcu() 在持有 rcu_gp_mutex 时不会获取任何锁,因此不会有死锁周期。
快速测验1: 为什么这争论幼稚? 在实际的Linux内核中使用此算法时,怎么会发生死锁?如何避免这种死锁?
5B. “玩具”实现 2:典型 RCU
本节介绍基于“经典RCU”的“玩具” RCU 实现。 它还缺乏性能(但仅用于更新),并且缺少如热插拔 CPU 和在 CONFIG_PREEMPT 内核中运行的功能。 rcu_dereference()和rcu_assign_pointer()的定义与上一节中的定义相同,因此将其省略。
void rcu_read_lock(void) { }
void rcu_read_unlock(void) { }
void synchronize_rcu(void)
{
int cpu;
for_each_possible_cpu(cpu)
run_on(cpu);
}
请注意,rcu_read_lock() 和 rcu_read_unlock() 绝对不做任何事。 这是非抢占式内核中经典 RCU 的强大优势: 读取侧开销恰好为零,至少在非 Alpha CPU 上是如此。 而且绝对不可能让 rcu_read_lock() 造成死锁!
syncnize_rcu() 的实现只是简单地依次在每个CPU上进行调度。 可以根据 sched_setaffinity() 原语直接实现 run_on() 原语。 当然,一个稍微不那么“玩具”的实现将在完成时恢复关联性, 而不是让所有任务都在最后一个CPU上运行, 但是当我说“玩具”时,我的意思是-玩具-!
那么这到底是怎么工作的呢???
请记住,在 RCU 读端临界区中被阻塞是非法的。 因此,如果给定的CPU执行上下文切换,我们知道它必须已经完成了所有先前的 RCU 读端临界区的工作。 一旦 所有 CPU 执行了上下文切换,则所有 CPU 执行上下文切换之前的 RCU 读端临界区的工作已完成。
因此,假设我们从其结构中删除了一个数据项,然后调用了 syncnize_rcu()。 一旦 syncnize_rcu() 返回,我们可以确保没有 RCU 读端临界区包含对该数据项的引用,因此我们可以安全地回收它。
快速测验2:举例说明典型 RCU 的读取侧开销为-负开销-。
快速测验3:如果在RCU的读取端临界区阻塞是非法的,那么你在 PREEMPT_RT 上会做什么呢?正常的自旋锁能阻塞哪里???
6. 读写锁定的模拟
尽管RCU可以以许多不同的方式使用,但是 RCU 普遍的用法类似于读写锁。 以下的统一和差异显示了 RCU 和 读写锁之间的紧密联系。
@@ -5,5 +5,5 @@ struct el {
int data;
/* Other data fields */
};
-rwlock_t listmutex;
+spinlock_t listmutex;
struct el head;
@@ -13,15 +14,15 @@
struct list_head *lp;
struct el *p;
- read_lock(&listmutex);
- list_for_each_entry(p, head, lp) {
+ rcu_read_lock();
+ list_for_each_entry_rcu(p, head, lp) {
if (p->key == key) {
*result = p->data;
- read_unlock(&listmutex);
+ rcu_read_unlock();
return 1;
}
}
- read_unlock(&listmutex);
+ rcu_read_unlock();
return 0;
}
@@ -29,15 +30,16 @@
{
struct el *p;
- write_lock(&listmutex);
+ spin_lock(&listmutex);
list_for_each_entry(p, head, lp) {
if (p->key == key) {
- list_del(&p->list);
- write_unlock(&listmutex);
+ list_del_rcu(&p->list);
+ spin_unlock(&listmutex);
+ synchronize_rcu();
kfree(p);
return 1;
}
}
- write_unlock(&listmutex);
+ spin_unlock(&listmutex);
return 0;
}
或者,给那些喜欢并排列表的人:

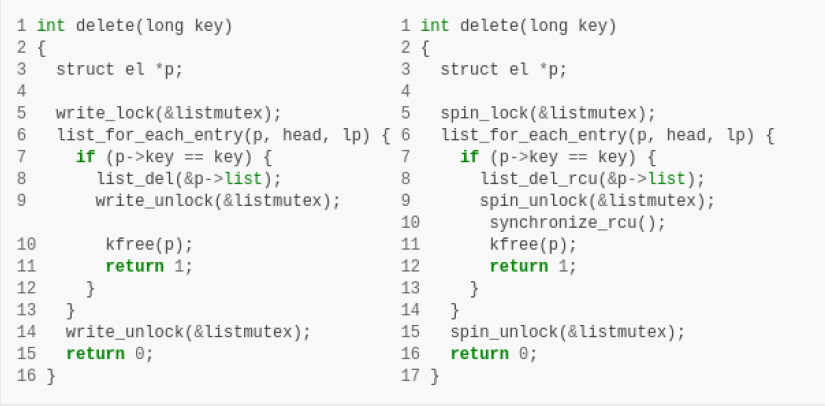
无论哪种方式,差异都很小。 读取侧锁移至 rcu_read_lock() 和 rcu_read_unlock(),更新端锁从读写锁移至简单的自旋锁, 并且 synchronize_rcu() 在 kfree() 之前。
但是,存在一个潜在的问题:读端和更新端临界区现在可以同时运行。 在许多情况下,这不是问题,但是无论如何都必须仔细检查。 例如,如果必须将多个独立的列表更新视为一个原子更新,则转换为RCU将需要特别注意。
另外,synchronize_rcu() 的存在意味着 delete() 的 RCU 版本现在可以被阻塞。 如果这是一个问题,那么可以使用一种永不阻塞的基于回调的机制, 即 call_rcu() 或 kfree_rcu() ,该机制可用于代替 另外,synchronize_rcu()。
7. 完整 RCU API 列表
RCU API 在 Linux 内核源代码中以 docbook 格式的注释头记录,但是它有助于获得API的完整列表, 因为似乎没有办法在 docbook 中对其进行分类。 这是按类别列出的列表。
| RCU list 遍历 |
|---|
| list_entry_rcu |
| list_first_entry_rcu |
| list_next_rcu |
| list_for_each_entry_rcu |
| list_for_each_entry_continue_rcu |
| list_for_each_entry_from_rcu |
| hlist_first_rcu |
| hlist_next_rcu |
| hlist_pprev_rcu |
| hlist_for_each_entry_rcu |
| hlist_for_each_entry_rcu_bh |
| hlist_for_each_entry_from_rcu |
| hlist_for_each_entry_continue_rcu |
| hlist_for_each_entry_continue_rcu_bh |
| hlist_nulls_first_rcu |
| hlist_nulls_for_each_entry_rcu |
| hlist_bl_first_rcu |
| hlist_bl_for_each_entry_rcu |
| RCU 指针/列表 更新 |
|---|
| rcu_assign_pointer |
| list_add_rcu |
| list_add_tail_rcu |
| list_del_rcu |
| list_replace_rcu |
| hlist_add_behind_rcu |
| hlist_add_before_rcu |
| hlist_add_head_rcu |
| hlist_del_rcu |
| hlist_del_init_rcu |
| hlist_replace_rcu |
| list_splice_init_rcu |
| hlist_nulls_del_init_rcu |
| hlist_nulls_del_rcu |
| hlist_nulls_add_head_rcu |
| hlist_bl_add_head_rcu |
| hlist_bl_del_init_rcu |
| hlist_bl_del_rcu |
| hlist_bl_set_first_rcu |
RCU:
| 临界区 | 宽限期 | 内存屏障 |
|---|---|---|
| rcu_read_lock | synchronize_net | rcu_barrier |
| rcu_read_unlock | synchronize_rcu | |
| rcu_dereference | synchronize_rcu_expedited | |
| rcu_read_lock_held | call_rcu | |
| rcu_dereference_check | kfree_rcu | |
| rcu_dereference_protected |
bh:
| 临界区 | 宽限期 | 内存屏障 |
|---|---|---|
| rcu_read_lock_bh | call_rcu | rcu_barrier |
| rcu_read_unlock_bh | synchronize_rcu | |
| [local_bh_disable] | synchronize_rcu_expedited | |
| [and friends] | ||
| rcu_dereference_bh | ||
| rcu_dereference_bh_check | ||
| rcu_dereference_bh_protected | ||
| rcu_read_lock_bh_held |
sched:
| 临界区 | 宽限期 | 内存屏障 |
|---|---|---|
| rcu_read_lock_sched | call_rcu | rcu_barrier |
| rcu_read_unlock_sched | synchronize_rcu | |
| [preempt_disable] | synchronize_rcu_expedited | |
| [and friends] | ||
| rcu_read_lock_sched_notrace | ||
| rcu_read_unlock_sched_notrace | ||
| rcu_dereference_sched | ||
| rcu_dereference_sched_check | ||
| rcu_dereference_sched_protected | ||
| rcu_read_lock_sched_held |
SRCU:
| 临界区 | 宽限期 | 内存屏障 |
|---|---|---|
| srcu_read_lock | call_srcu | srcu_barrier |
| srcu_read_unlock | synchronize_srcu | |
| srcu_dereference | synchronize_srcu_expedited | |
| srcu_dereference_check | ||
| srcu_read_lock_held |
| SRCU: 初始化/清理 |
|---|
| DEFINE_SRCU |
| DEFINE_STATIC_SRCU |
| init_srcu_struct |
| cleanup_srcu_struct |
| All: 锁定检查 RCU 保护的指针访问 |
|---|
| rcu_access_pointer |
| rcu_dereference_raw |
| RCU_LOCKDEP_WARN |
| rcu_sleep_check |
| RCU_NONIDLE |
有关更多信息,请参见源代码(或由此生成的 docbook)中的注释头。
但是,鉴于 Linux 内核中至少有四个RCU API系列,你如何选择使用哪个? 以下列表可能会有所帮助:
- 读者需要阻塞吗? 如果是需要,你要用 SRCU。
- 那-rt补丁集呢? 如果读者需要在非 rt 内核中进行阻塞,则需要 SRCU。 如果读者要在 rt 内核中阻塞,而在非 rt 内核中不阻塞,则SRCU是不必要的。 (-rt 补丁集将自旋锁转换为睡眠锁,因此有区别。)
- 你是否需要 NMI 处理程序,硬件中断处理程序和禁用了抢占功能的代码段 (无论是通过 preempt_disable(), local_irq_save(), local_bh_disable() 还是其他某种机制) 作为显式 RCU 读者?如果是这样,RCU 调度是唯一适合你的选择。
- 即使面对由软中断独占的一个或多个CPU,你是否也需要在 RCU 宽限期来完成? 例如,你的代码是否遭受基于网络的拒绝服务攻击? 如果是这样,则应在所有读者之间禁用 softirq,例如,通过使用 rcu_read_lock_bh()。
- 对于正常使用 RCU,你的工作量是否更新密集,但对于其他同步机制却不合适? 如果是这样,请考虑 SLAB_TYPESAFE_BY_RCU(最初名为SLAB_DESTROY_BY_RCU)。 但是请小心!
- 你是否要在空闲循环的中间,在用户模式执行期间或在脱机的CPU上也需要读端临界区? 如果是这样,SRCU是唯一适合你的选择。
- 除此之外用 RCU.
当然,所有这些都假定你已经确定 RCU 实际上是工作的正确工具。
8. 快速测验答案
快速测验1: 为什么这争论幼稚? 在实际的Linux内核中使用此算法时,怎么会发生死锁?[参考基于锁的“玩具”RCU算法。]
答:请考虑以下事件序列:
1. CPU 0 获取一些无关的锁,将其称为“ problematic_lock”,并通过 spin_lock_irqsave() 禁用中断。 2. CPU 1 进入 synchronize_rcu(),并获取 rcu_gp_mutex。 3. CPU 0 入 rcu_read_lock(),但必须等待,因为 CPU 1 保留 rcu_gp_mutex。 4. CPU 1 被中断,并且中断处理程序尝试获取 problematic_lock。
系统现在已死锁。
避免这种死锁的一种方法是使用类似 CONFIG_PREEMPT_RT 的方法,在该方法中, 所有普通的自旋锁都变为阻塞锁,并且所有中断处理程序都在特殊任务的上下文中执行。 在这种情况下,在上面的步骤4中,中断处理程序将阻塞,从而允许 CPU 1 释放 rcu_gp_mutex,从而避免死锁。
即使没有死锁,该 RCU 实现也允许通过延迟 syncnize_rcu() 从读者“泄漏”到其他读者。 为此,请考虑 RCU 读端临界区的任务A(因此,保持读状持有 rcu_gp_mutex), 任务 B 尝试写入-获取 rcu_gp_mutex 被阻塞,任务 C 阻塞在 rcu_read_lock() 中尝试获取 rcu_gp_mutex。 任务 A 的 RCU 读取时延阻止了任务 C,尽管是间接通过任务 B。
因此,实时 RCU 实现使用基于计数器的方法,其中 RCU 读端临界区中的任务不能被执行中的 syncnize_rcu() 任务阻塞。
快速测验2:举例说明典型 RCU的读端开销为-负开销-。
答:想象一个具有非 CONFIG_PREEMPT 内核的单 CPU 系统,其中进程表代码使用路由表, 但可以通过irq上下文代码(例如,通过“ ICMP REDIRECT”数据包)对其进行更新。 解决此问题的常用方法是在搜索路由表时搜索过程的上下文代码禁用中断。 使用RCU可以取消这种中断禁用。因此,如果没有RCU,则要付出禁用中断的代价,而有了RCU,则不必。
可以认为,在这种情况下,RCU的开销相对于单CPU中断禁用方法为负。 其他人可能会争辩说,RCU的开销仅仅是零,并且用零开销RCU方案代替中断禁用方案的正开销并不构成负开销。
当然,在现实生活中,事情会更加复杂。但是,即使是从理论上讲,同步原语产生负开销的可能性也是有点意外的。 😉
快速测验3:如果在RCU的读取端临界区阻塞是非法的,那么你在 PREEMPT_RT 上会做什么呢?正常的自旋锁能阻塞哪里???
答案:就像 PREEMPT_RT 允许抢占自旋锁临界区一样,它也允许抢占 RCU 读端临界区。在RCU的读端临界区中,它还允许自旋锁阻塞。
为什么出现明显的不一致?因为可以根据需要提升优先级来使 RCU 宽限期保持较短(例如,如果内存不足)。 相反,如果阻塞等待(发言)网络接收,则无法知道应该提高什么。 特别是考虑到我们需要提高优先级的进程很可能是一个人,他只是出去吃披萨什么的。 尽管电脑操作的牛棒可能会引起人们的极大兴趣,但也可能引起人们的强烈反对。此外,计算机如何知道人类去了什么比萨店???
致谢
我感谢那些使这篇文档让人类可读的人,包括J on Walpole, Josh Triplett, Serge Hallyn, Suzanne Wood 和 Alan Stern。
有关更多信息,请参见http://www.rdrop.com/users/paulmck/RCU。